機器學習的主要步驟為:收集數據、訓練模型、部署模型;
而數據科學是:收集數據 、分析數據、建議修改。
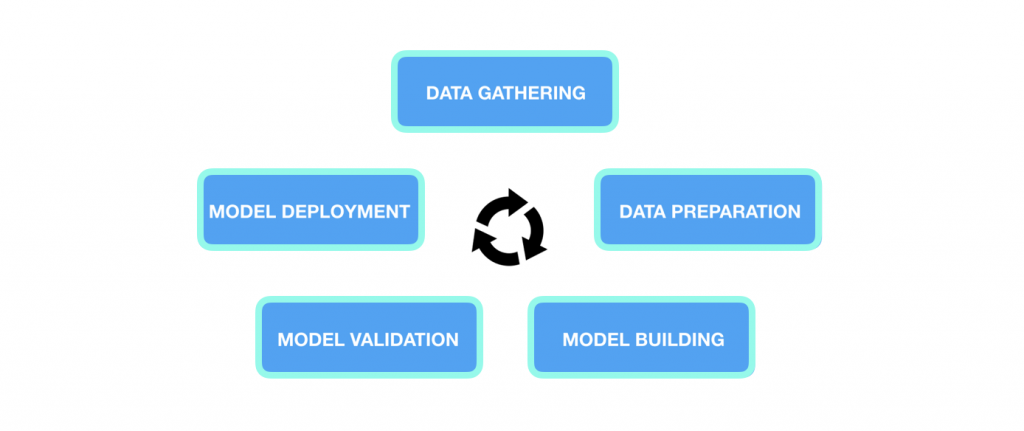
(以AI for everyone的教材內容作為範例)
我們使用Amazon智慧音箱Alexa來作為例子,其機器學習的關鍵步驟如下:

- 收集數據:智慧音箱都有一個關鍵詞,Amazon選擇了"Alexa"、小米選擇了"小愛同學",當我們想讓機器學習系統去偵測用戶是否說出了關鍵詞進而決定是否要喚醒裝置,第一步要做的就是收集數據,讓一些人說出"Alexa"並且錄制下來,除此之外也需要收集其他的語音,例如"Hi"、"How are your"
- 訓練模型:機器學習需要開始訓練去學習接收到某些音頻後的應對,例如聽到喚醒詞要回應"什麼事?“,用戶發問天氣如何,就必須要回答天氣預報的內容。為了達到使我們滿意的內容,可能需要多方嚐試,或者讓產品不停地疊代。
- 部署模型:這意味著你把訓練到一定程度的產品放到一個真正的智慧音箱中,然後把它寄給測試用戶,又或者是產品上市了,你收到用戶的回饋,更多的數據。此時你需要好好利用新的數據來維護並升級你的模型,工作流程回到步驟1,最後機器學習模型的質量便隨著此迴圈而不斷地成長。


 iThome鐵人賽
iThome鐵人賽